【使用 Rust 写 Parser】3. 解析JSON
上一篇文章中我们使用 nom 解析了 redis 协议, 本次我们将会尝试写一个 JSON parse, 同时熟悉 nom 的错误处理. 本篇例子来自 nom 官方文档的例子nom/examples/json.rs, 做了 一些修改以便可以在 nom 5.1 版本可以运行且符合标准描述.
经常进行 web 编程的想必都非常熟悉 JSON, 它被广泛用于数据传递, 要想实现了 JSON parse, 我们需要了解它的标准. JSON标准网站上给出非常详细的 JSON 标准解释, 而且还带有图表(下面使用的图标均来自 https://www.json.org/json-zh.html), 我们需要做的只是参照标准 利用 nom 从基本元素开始一步步实现 JSON parse.
JSON标准 分6部分对 JSON 标注进行解释, 从简单到复杂为:
- 空白(whitespace)
- 数值(number)
- 字符串(string)
- 值(value)
- 数组(array)
- 对象(object)
我们可以用一个枚举代表除空白外的解析值
#[derive(Debug, PartialEq)] pub enum JsonValue { Str(String), Boolean(bool), Null, Num(f64), Array(Vec<JsonValue>), Object(HashMap<String, JsonValue>), }
空白
空白可以加入到任何符号之间
其完整描述为
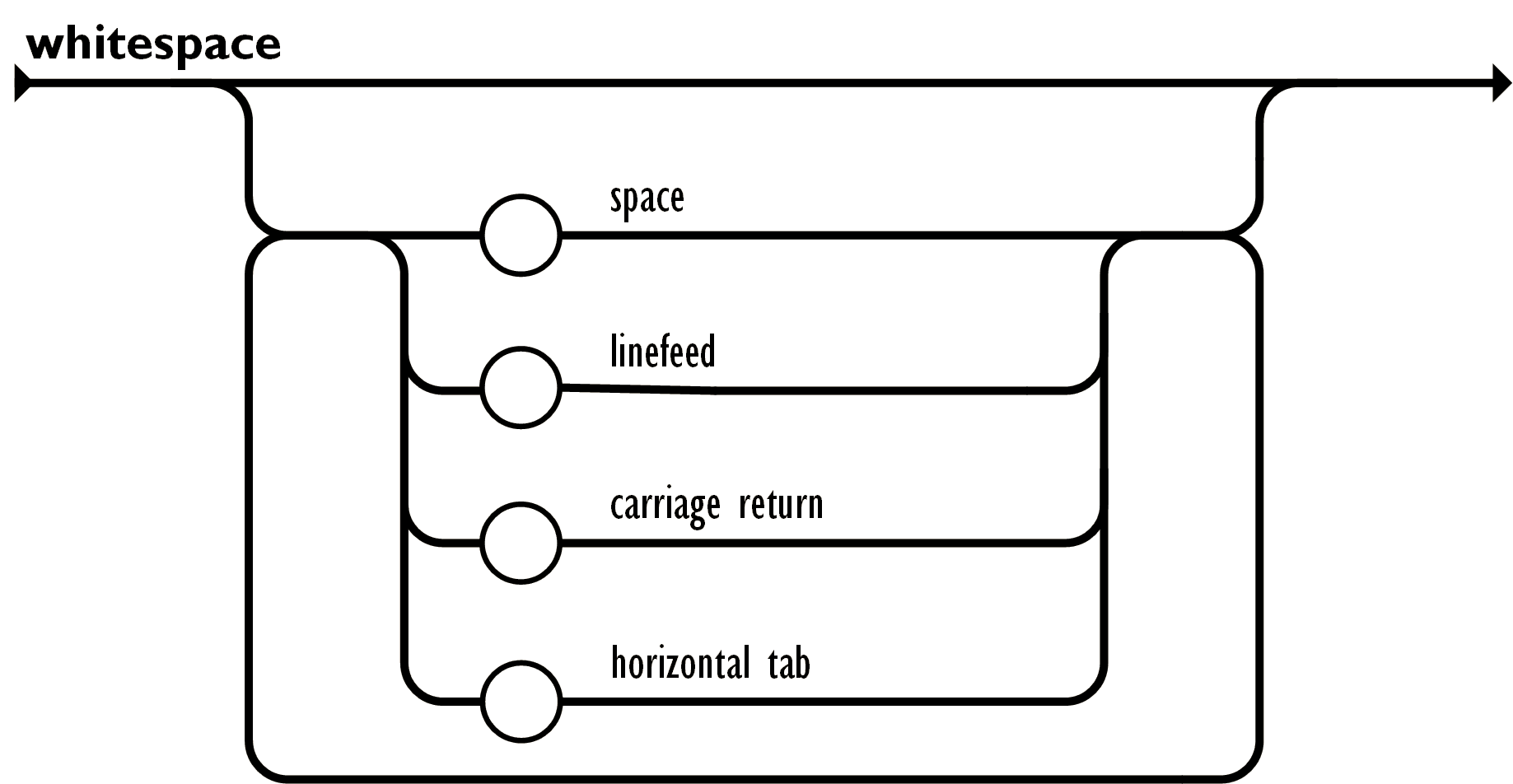
可以看到空白元素为 “ “ -> space, “\n” -> linefeed, “\r” -> carriage return 和 “\t” 中任意一个. 对输入的字符进行判断, 如果它是4个空白字符之一, 消耗输入并继续, 直到遇到其他元素, 这时我们就得到了一个“空白“.
使用 nom 的 take_while 可以很快地帮我们实现 whitespace parse
fn sp(i: &str) -> IResult<&str, &str> { let chars = " \n\r\t"; take_while(move |c: char| chars.contains(c))(i) }
但其实 nom 已经自带了一个空白解析函数 multispace0, 可以根据个人喜好使用.
数值
数值(number)也与C或者Java的数值非常相似
其完整描述为
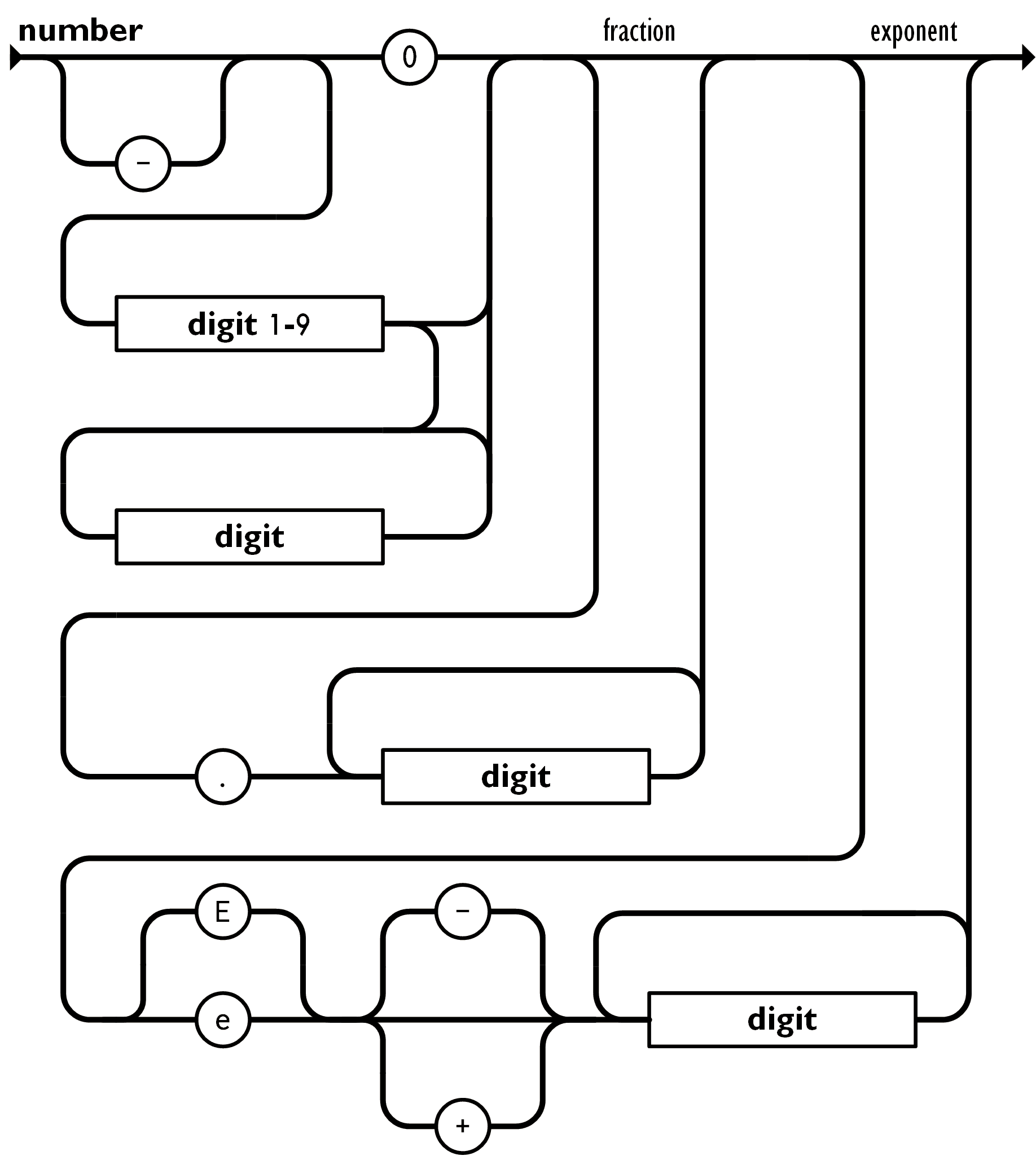
可以看到 JSON 支持正负数, 小数和科学计数法, 我们可以使用 alt 和 be_f32 等解析子组合进行解析, 但对于数值解析这样的常见需求, nom 提供了现成的 double 函数.
use nom::number::complete::double; let parser = |s| { double(s) }; assert_eq!(parser("1.1"), Ok(("", 1.1))); assert_eq!(parser("123E-02"), Ok(("", 1.23))); assert_eq!(parser("123K-01"), Ok(("K-01", 123.0))); assert_eq!(parser("abc"), Err(Err::Error(("abc", ErrorKind::Float))));
而且在 nom 5 使用了 lexical crate 解析浮点数, 相比 nom 4, 浮点数解析快了 98%, 我们可以放心使用 nom 进行浮点数解析.
字符串
字符串(string)是由双引号包围的任意数量Unicode字符的集合,使用反斜线转义。一个字符(character)即一个单独的字符串(character string)
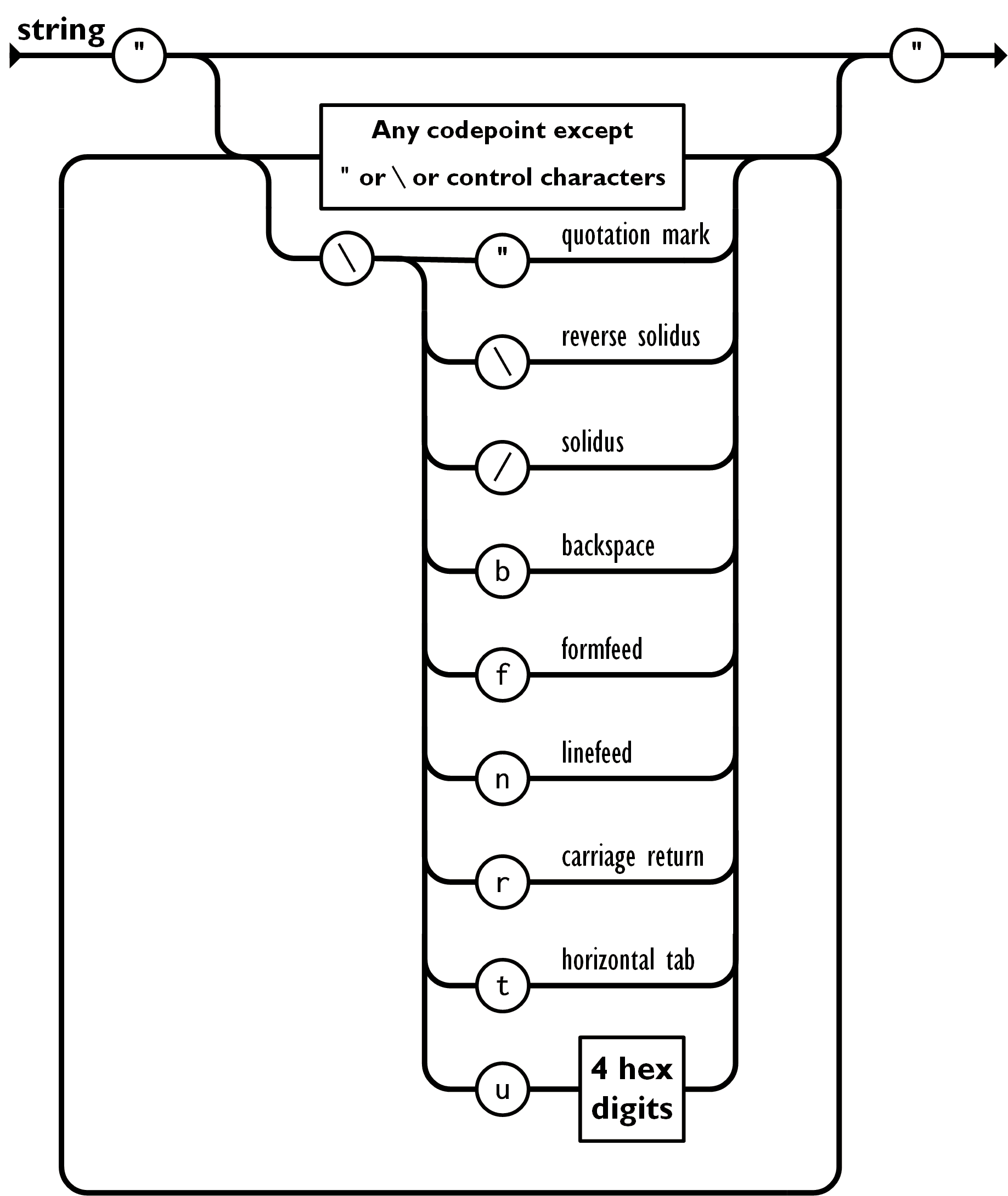
从图中可以看到左引号之后有3种情况, 最特殊的情况为两个引号之间无任何元素, 即空字符,
其他两种情况我们可以使用 delimited 去掉两端的引号, 拿到字符串内容.
fn string(i: &str) -> IResult<&str, &str> { context( "string", alt((tag("\"\""), delimited(tag("\""), parse_str, tag("\"")))), )(i) }
这里使用 context 为我们解析提供了一个上下文信息, 因为 parse_str 函数比较复杂, 涉及很多基本解析, 容易与数值, 数组, 对象等解析错误抛出的信息混淆,
添加一个上下文环境可让让我们方便地知道是在解析 string 时出了问题.
之后的测试中将会展示 context 为我们提供的额外信息.
现在我们要实现关键的 parse_str 函数, 我们面临的最大难题是处理转义字符, nom 同样为我们提供了处理转义字符的函数 escaped.
这个函数签名为 escaped(normal, control, escapable), 即接受三个参数, normal 为判断普通字符函数, 必须不含有控制符 control, escapable 则是可以转义的字符.
官方文档的例子可以更形象地展示其用法:
use nom::bytes::complete::escaped; use nom::character::complete::one_of; fn esc(s: &str) -> IResult<&str, &str> { escaped(digit1, '\\', one_of(r#""n\"#))(s) } assert_eq!(esc("123;"), Ok((";", "123"))); assert_eq!(esc(r#"12\"34;"#), Ok((";", r#"12\"34"#)));
所以 parse_str 可以这样实现:
fn parse_str(i: &str) -> IResult<&str, &str> { escaped(normal, '\\', escapable)(i) }
normal 同样是一个解析函数, 按照标准中描述的
Any codepoint except “ or \ or control characters
我们只需要一直消耗输入, 直到碰上 “ \ 或控制字符, take_till1 就可以实现我们的需求, 它与 take_while 用法相似.
fn normal(i: &str) -> IResult<&str, &str> { take_till1(|c: char| c == '\\' || c == '"' || c.is_ascii_control())(i) }
注意, 这里使用了 take_till1, 即至少需要消耗1个char, 如果使用 take_till, 会导致 escaped 内部无限循环, 感兴趣的可以查看 escaped实现源码.
处理可转义字符的 escapable 函数除了处理16进制稍微麻烦点外, 可以使用 alt 和 tag 实现.
fn escapable(i: &str) -> IResult<&str, &str> { context( "escaped", alt(( tag("\""), tag("\\"), tag("/"), tag("b"), tag("f"), tag("n"), tag("r"), tag("t"), parse_hex, )), )(i) } fn parse_hex(i: &str) -> IResult<&str, &str> { context( "hex string", preceded( peek(tag("u")), take_while_m_n(5, 5, |c: char| c.is_ascii_hexdigit() || c == 'u'), ), )(i) }
parse_hex 使用了 peek, 这个函数的不同之处在于它会尝试对输入应用解析函数, 而不消耗输入. 以上面的代码为例, 假设输入为 i = "u1234", peek(tag("u") 应用之后传入 take_while_m_n 的输入依然为 "u1234", 若只使用tag("u"), take_while_m_n 接收到的只有 1234.
值
值(value)可以是双引号括起来的字符串(string)、数值(number)、true、false、 null、对象(object)或者数组(array)。这些结构可以嵌套。
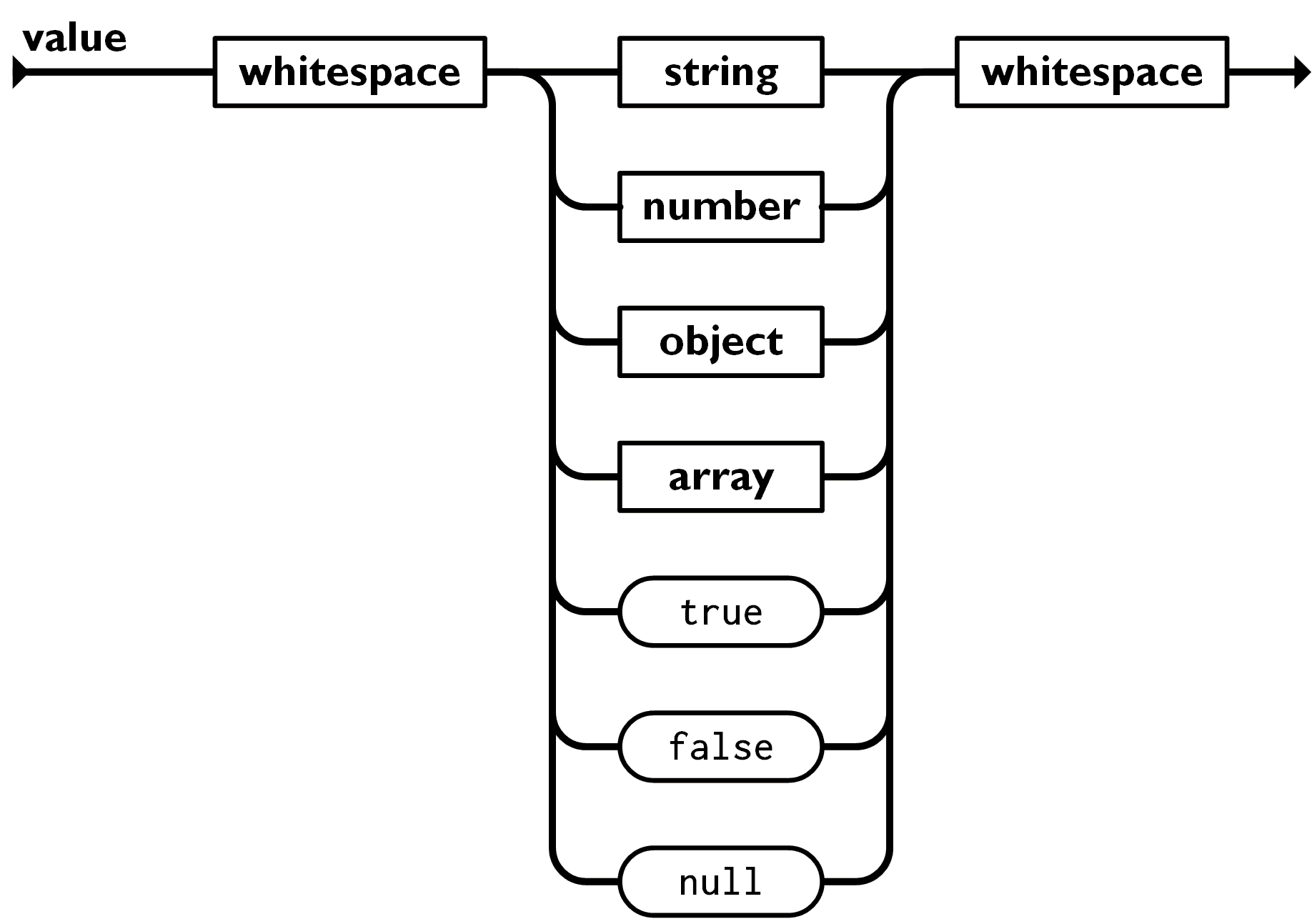
可以看到值的解析比较简单, 空白,字符串和数字的解析我们都已经完成了, 剩下的只有基本类型 true, false 和 null 以及复合类型 object 和 array.
先完成基本类型解析
fn boolean(i: &str) -> IResult<&str, bool> { let parse_true = n_value(true, tag("true")); let parse_false = n_value(false, tag("false")); alt((parse_true, parse_false))(i) } fn null(i: &str) -> IResult<&str, JsonValue> { map(tag("null"), |_| JsonValue::Null)(i) }
在解析布尔值时使用了 n_value, 它其实是 nom::combinator::value, 只不过被我重命名为 n_value, 这个函数会在子解析成功时返回提供的值,
以上面代码为例, 如果 tag("true") 成功, 那么 n_value(true, tag("true")) 将返回 true.
object 和 array 的实现暂时不管, 值的解析可以写为
fn value(i: &str) -> IResult<&str, JsonValue> { context( "value", delimited( multispace0, alt(( map(object, JsonValue::Object), map(array, JsonValue::Array), map(string, |s| JsonValue::Str(String::from(s))), map(double, JsonValue::Num), map(boolean, JsonValue::Boolean), null, )), multispace0, ), )(i) }
在实现 value 时使用了一个小 trick, map 的第二个参数应该是一个匿名函数, 如 map(string, |s| JsonValue::Str(String::from(s))) 这样的写法,
但 Rust 枚举成员构造函数本身就是一个匿名函数, 所以 map(double, |num: f64| JsonValue::Num(num)) 可以简化为 map(double, JsonValue::Num).
数组
数组是值(value)的有序集合。一个数组以 [左中括号 开始, ]右中括号 结束。值之间使用 ,逗号 分隔。
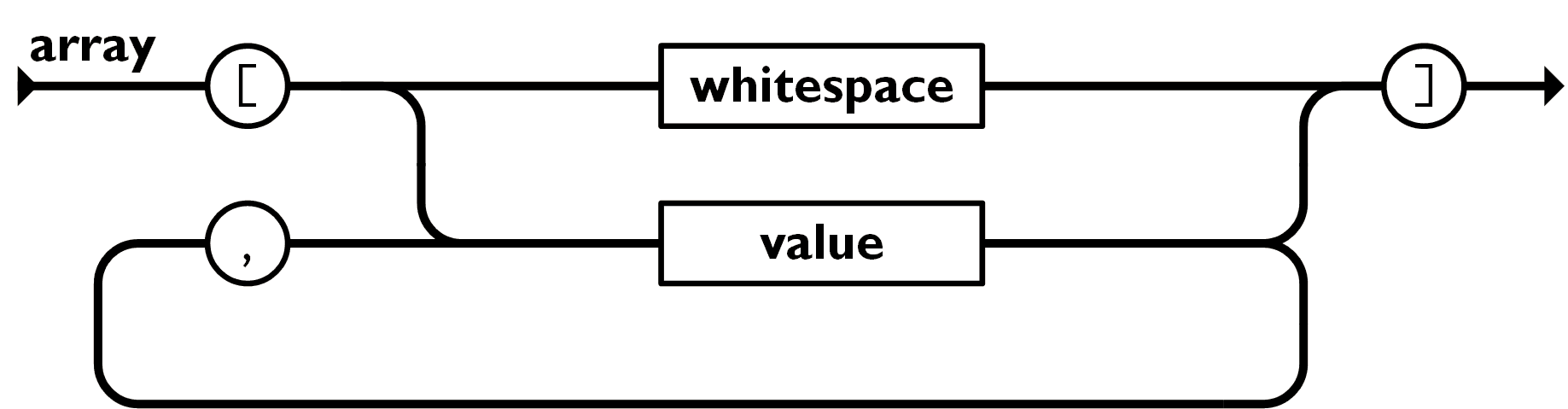
我们用 delimited 去掉左右方括号, 然后利用 separated_list 对方括号剑的内容进行解析, 得到 Vec<JsonValue>
fn array(i: &str) -> IResult<&str, Vec<JsonValue>> { context( "array", delimited( tag("["), separated_list(tag(","), delimited(multispace0, value, multispace0)), tag("]"), ), )(i) }
需要注意的是, 在 value 两侧可能会有空白, 如
{ "array": ["ab", "cd" , "ef" ]}
这些空白不会被 value 消耗, 需要将其视为数组某元素内容, 在解析时消耗掉.
对象
对象是一个无序的“‘名称/值’对”集合。一个对象以 {左括号 开始, }右括号 结束。每个“名称”后跟一个 :冒号 ;“‘名称/值’ 对”之间使用 ,逗号 分隔。
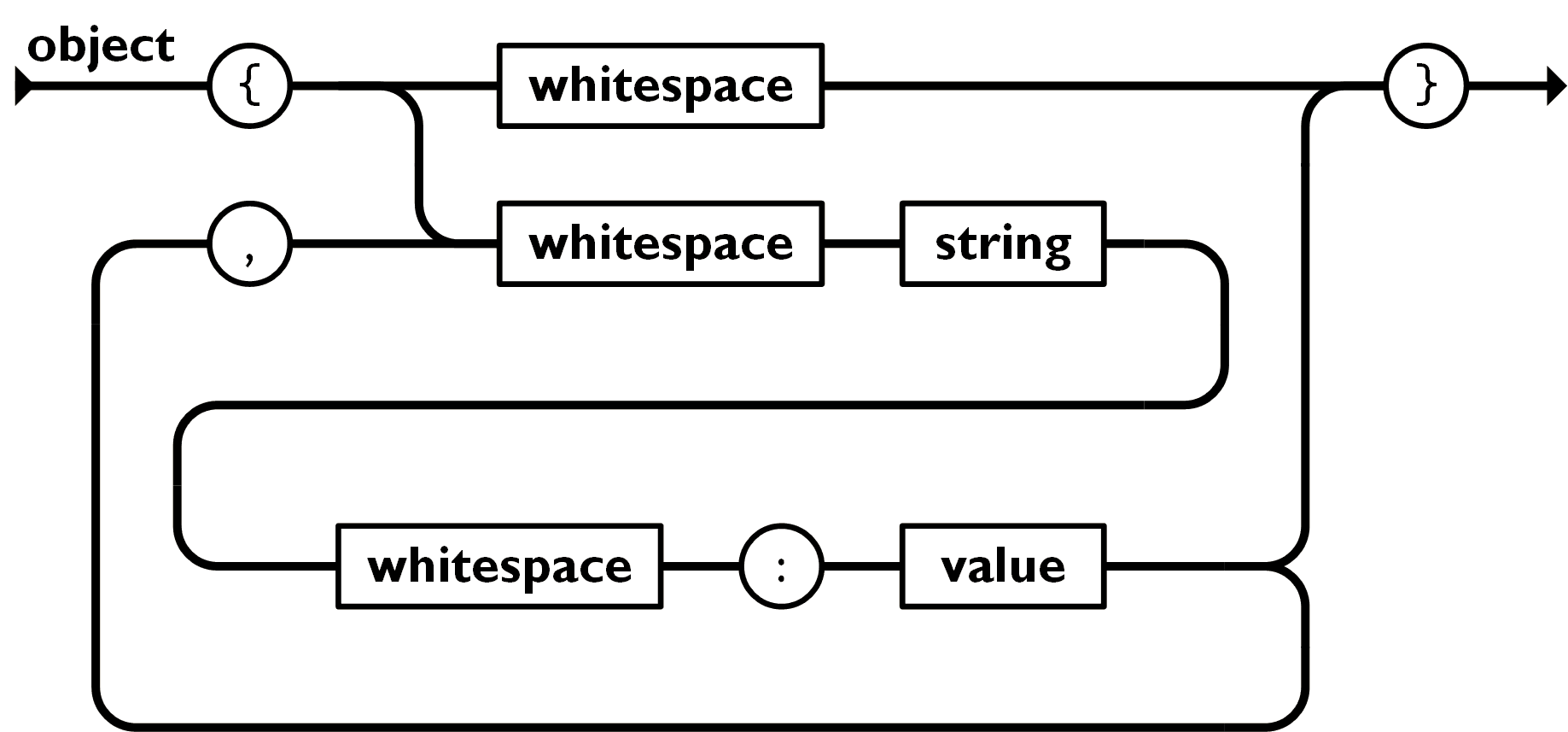
对象结构与数组类似, 不同的是我们需要解析键和值, 然后把他们拼接起来. 先实现键的解析.
fn key(i: &str) -> IResult<&str, &str> { delimited(multispace0, string, multispace0)(i) }
值解析我们已经实现, 现在需要把他们拼起来
fn object(i: &str) -> IResult<&str, HashMap<String, JsonValue>> { context( "object", delimited( tag("{"), map( separated_list( tag(","), separated_pair(key, tag(":"), delimited(multispace0, value, multispace0)), ), |tuple_vec: Vec<(&str, JsonValue)>| { tuple_vec .into_iter() .map(|(k, v)| (String::from(k), v)) .collect() }, ), tag("}"), ), )(i) }
object 实现有些复杂, 最外层的 delimited 去掉左右大括号, 接着用 map 对 separated_list 解析得到的 Vec<(&str, JsonValue)> 进行转换, 得到预期的 Hashmap<String, JsonValue>.
对于每个键值对我们都用 separated_pair 去掉分隔符, 得到键值.
最后需要对顶层结构进行解析, 一个顶层结构类型只能是对象或数组
fn root(i: &str) -> IResult<&str, JsonValue> { delimited( multispace0, alt((map(object, JsonValue::Object), map(array, JsonValue::Array))), multispace0, )(i) }
总结
至此一个 JSON parse 已经完成了, 如果想查看完整代码和测试可以到我的 repo PrivateRookie/jsonparse 查看.
整个项目代码包括测试代码共 263 行
------------------------------------------------------------------------------- Language Files Lines Code Comments Blanks ------------------------------------------------------------------------------- Markdown 1 2 2 0 0 Rust 2 277 254 0 23 TOML 1 10 7 1 2 ------------------------------------------------------------------------------- Total 4 289 263 1 25 -------------------------------------------------------------------------------
比上次解析 redis 协议的项目代码行数还要少, 可见 nom 配合 Rust 可以取得很好的表达能力. 但这个项目没有经过完整测试, 同时没没有进行性能测试, 有兴趣的可以去尝试.
下一期按计划应该是使用 nom 实现一门语言, 但这样的话只介绍了 nom 解析文本的能力, 其实 nom 可以解析二进制, 比如 mysql binlog. 下次什么内容什么时间还是看心情吧😊.